챗GPT의 중요성이 부각되고 있는 요즘 많은 분들이 이 녀석의 활용방법에 대해 고민하고 있고 일단 문장을 생성해낸다는 장점으로 첫번째 과제나 1차적인 텍스트 창작물에 대해 많이 관심을 가지고 계실 것 같아요. 그럼 이 저작권에 대한 문제는 차치하더라도, 이게 과연 검출이나 사용여부를 알아낼 수 있는 방법이 있을지 한번 알아봐요.
-
챗GPT 저작권문제
-
GTP 생성물 검출방법
-
검출은 어떻게 하나
-
사용이 문제가 되나
챗GPT 저작권문제
현재 챗 GPT가 만들어낸 답변이나 저작물에 대한 저작권 판단이 명확하지가 않아요 새로 부각되기 시작한 기술이기도 하고 원작자의 저작권은 어떻게 인정할 것이냐에 대한 문제도 남아 있기 때문에 명확하진 않지만 일단 챗 GPT의 답변을 그대로 사용한 다는건 출처 여부를 떠나서 저작권 문제에 직면할 수 밖에 없을 듯 합니다 일단 두가지의 문제인데요
-
원작자 데이터의 인정여부
-
GPT 생성 데이터의 소유권한 여부
이 두가지가 쟁점이 될 듯한데요, 제가 이리저리 자료를 찾아보니 아직까지 명확히 이렇다할 논의나 법제화는 없었기 때문에 아직은 합법이라기보다는 무법에 가깝다 봐야겠습니다만, 추후라도 그대로 베껴쓰는건 문제가 될 것으로 예상됩니다.
GPT 생성데이터 검출 방법
그럼 앞으로 이 인공지능의 답변에 대한 검출이 새로운 문제로 두각될 듯 한데요 비슷한 패턴을 자기고 있긴 해도 매번 다르게 답변을 하기도 하고, 사용자가 수정할 가능성이 높기 때문에 이렇게 변형된 자료를 검출해낼 수 있는 냐입니다. 검출 방법에는 크게 3가지가 있다고 합니다
-
비인간적 패턴 찾기
-
사전 데이터와 비교분석
-
기존 생성데이터와 텍스트 유사성
같은 방법으로 찾게 된다는데요 그래서 현재는 이 GPT 생성물인지 아닌지를 검증하는 도구들이 많이 출시되어 연구 되는 중입니다 아쉽지만 아직 한글전용 도구는 없지만 영어를 검출할 수 있는 도구들은 상당히 많습니다.
검출은 어떻게?

How to make money with gpt. 에 대한 질문의 답변입니다.
이 답변은 그대로 검출기에 넣어보겠습니다.
검증과정을 거친후 답변
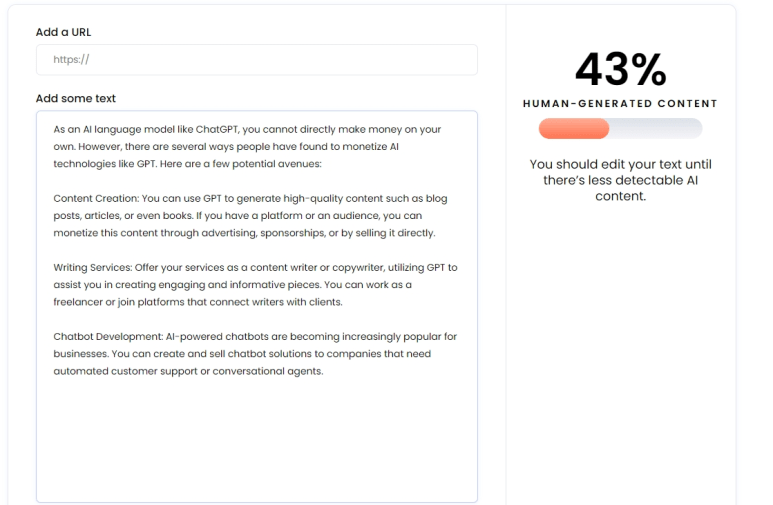
43퍼센트라는 결과를 보여줍니다. 여러가지 직접 테스트 해볼 결과 어떤 답변은 거의 잡아내질 못하고 어떤 것은 거의 100% 라고 알려줍니다… 이건 gpt가 발전하면 할 수록 디텍팅 기술도 발전해야 할 것으로 보이는데요..
결국은 사람이 직접 읽어보지 않으면 100% 걸러내기는 어려울 것으로 보이고 심지어 사람이 읽는다 하여도, 자연스러운 수정이 가해졌다면 이걸 걸러낸다는게 가능할까 정도입니다 다만 GPT들은 원 데이트를 가공하기 때문에 원 데이터에 대한 신뢰도, 그리고 잘못된 답변을 하기 때문에 그대로 베껴서 쓴다면 문제가 될 수 밖에 없기에 보조의 역활로 써야 겠습니다.